

当编写程序代码时,我们需要花费大量的时间用于定义、读取和修改变量。使用变量意味着在代码中利用一个有字面意义的词语来代表一些特定信息(一组数字,一些文字,一个对象等)。这个词语是这些信息的“标题”。举例来说:
变量为程序编写提供了便利,你不必去关心你的数据被存放在内存中的哪个地方。你只需定义一个变量,给出相应的计算规则,然后从一个函数中传递给另一个函数。计算机会在内存中自动处理这段数据。
然而,有时我们如果了解变量背后发生了什么是很重要的。尤其是对于低级别的语言(如Assembler或C)来说,有时知道变量被存储在哪里是必要的。这篇文章讲解释变量是如何从两个函数中被传递,特别是如何在Java中工作的。在Java中,变量传递的两种方式:传值(pass by value)和引用(pass by reference)之间有些微但重要的区别。
什么是参数传递(pass a variable)
「passing a variable」是指调用一个函数时,使用之前定义过的一个变量

变量「myAge」被传递给函数「calculateBirthYear」中。意味着这个函数可以使用这个变量,
在传递变量「myAge」时,有两种方法,即「pass by value」和「pass by reference」。
「pass by value」意味着传递的是这个变量实际的值value;而「pass by reference」意味着传递的是存放value的内存地址。
内存是如何工作的
了解内存如何工作以及变量如何存放在内存中有助于更好地理解整个概念。
对于大多数的编程人员(尤其是初学者),了解到一些概念就足够了。但一旦掌握了一些编程知识后,进一步了解数据存储知识(硬盘、RAM、heap、stack等)是非常有用的。

内存可以被想象为一个挨一个的“块(blocks)”,每一块都有一串数字作为内存地址。如果在代码中定义了一个变量,变量的值就被存储在一块内存中。系统会自动划分出最佳的存储位置。
上图中灰色数字(101,102或106)代表内存中存储块的地址。格子中的彩色数字代表变量的值。
代码中定义了变量「myAge」和「month」,它们在内存中分别被存储在地址106和113中。
Pass by value
「pass by value」意味着这个函数参数的value被copy进内存中的另一个位置(见下图),当在函数中访问或修改这个变量时,只有这个copy复制品被操作了,而原始的value没有被接触到。
内存中的value被copy到另一个地址,并在函数中被使用。
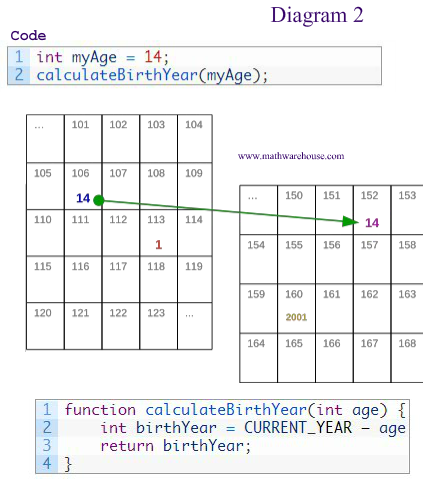
当程序开始执行函数「calculateBirthYear」时,「myAge」的值被copy到计算机内存的另外一个地点。为使这个步骤更清晰,在函数内部,这个变量被称为「age」
对「age」进行的任何操作不会影响「myAge」的值。
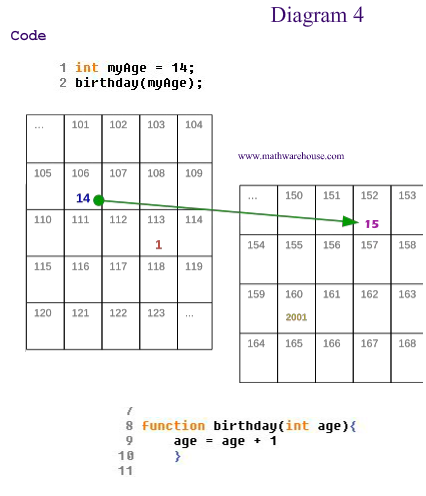
假如我们在函数内更改birthday「int age」(如图4),使变量「age」增加,并不会改变原来的「myAge」的值。因为你可以从图中看到,「myAge」被存在106中,但「age」被存在152中。所以当执行第9行(age = age + 1)后,不会对「myAge」产生任何影响。
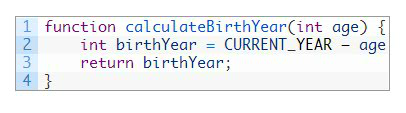
如何修改原有参数的值?
如何在函数内修改变量,从而影响函数外变量的值?当通过「pass by value」来传递参数时,如想更新原数据只能通过「return value」来进行。这意味着只能更新函数外的一个参数值。
下方的这段代码显示了用「return」来编辑一个变量的值

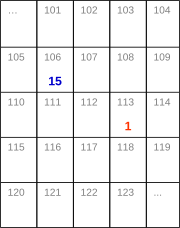
经过「return」之后在内存中原变量已经更近了value,现在「myAge」的值已经是15.
Pass by Reference
「Pass by reference」是指变量的存储地址(一个内存位置的指针)被传递到函数中,在这一点上与「pass by value」不同。在下例中,「myAge」的内存地址是106,当传递「myAge」给函数increaseAgeByRef时,函数中的变量(本例中的age)仍然指向原来变量「myAge」的相同内存地址(提示:&符号是指获取变量的reference/pointer)
当调用这个函数时,「myAge」的value也会被修改。现在「myAge」的值是15.
修改多个值
通过「pass by reference」,可以在函数内修改多个变量。此外还可以通过「return」来修改一个变量的值(经常是一个状态,成功或失败或最重要的变量),如:

为了决定是「pass by value」还是「pass by reference」,有两条简单的规则:
- 如果想要函数返回一个单值,用「pass by value」
- 如果想要函数返回两个或更多的值,用「pass by reference」
此外,在使用arrays或structures(或high-level languages的对象)时,尽量避免使用「pass by reference」。
以下是基于Python的参数传递规则:
在Python中有三种基本的函数调用办法:
- pass by value
- pass by reference
- pass by object reference
python is a pass by object reference language, 首先要理解变量和变量的值(对象)是两个独立的事物。变量「指向」对象,变量不是对象。
变量不是对象
x = [][ ]是一个空的list,x是一个指向这个空list的变量,但x本身不是这个空list。
可以把变量(上述的x)考虑成一个带标签的箱子,而变量的值([ ])视作箱子中的物品对象。
Pass by object reference
来看一个「Object references are passed by value」的例子:
def append_one(li):
li.append(1)
x = [0]
append_one(x)
print xx = [0]表示变量x(箱子)指向对象[0]。
在调用函数时,一个新的箱子「li」被创建出来,「li」的内容和x的内容一样。这两个箱子含有相同的对象。这说明这两个变量指向内存中相同的地址。因此「li」的任何改动会反映在x所指向的对象上。
所以上面这段代码的输出结果是[0,1].
注意:如果变量「li」在函数内重新被赋值,那么「li」将会指向内存中另外的地址。而x仍将指向内存中原来的地址。如
def append_one(li):
li = [0, 1]
x = [0]
append_one(x)
print x这段代码的输出结果是[0]
Pass by reference
在参数传递过程中,箱子中的内容(参数的值)被传送到函数中。因此在函数中对于值的任何变化将会影响原有的参数。
Pass by value
一个新的箱子(参数)在函数中被创建,并且copy原有箱子中的内容,存放在新箱子里。
参考:
Pass By Value vs Pass By Reference
https://stackoverflow.com/questions/13299427/python-functions-call-by-reference
